
앞선 글에서 테이블 조인시 데이터 중복 제거를 했다
하지만 성능이 별로 좋지 못한듯 하다
(해당 소요시간은 네트워크 환경,시스템 지연시간 등을 포함한 시간인것 같다)

이번 기회에 쿼리 성능을 높혀보자
기존 쿼리
ORM
const query = this.placeRepository
.createQueryBuilder('place')
.leftJoin('place.rating', 'rating')
.leftJoin('place.carts', 'cart')
.select([
'place.id',
'place.address AS address',
'place.image AS image',
'place.title AS title',
'place.mapx AS mapx',
'place.mapy AS mapy',
'place.viewCount AS viewCount',
])
.addSelect('AVG(rating.ratingValue)', 'averageRating')
.addSelect('COUNT(DISTINCT rating.id)', 'reviewCount')
.addSelect('COUNT(DISTINCT cart.cartId)', 'saveCount')
.skip((searchOption.page - 1) * searchOption.limit)
.take(searchOption.limit)
.groupBy('place.id');
SQL
SELECT `place`.`id`, `place`.`address` AS address, `place`.`image` AS image, `place`.`title` AS title, `place`.`mapx` AS mapx, `place`.`mapy` AS mapy, `place`.`view_count` AS viewCount, AVG(`rating`.`ratingValue`) AS `averageRating`, COUNT(DISTINCT `rating`.`id`) AS `reviewCount`, COUNT(DISTINCT `cart`.`cartId`) AS `saveCount`
FROM `place` `place`
LEFT JOIN `place_rating` `rating` ON `rating`.`placeId`=`place`.`id`
LEFT JOIN `cart` `cart` ON `cart`.`placeId`=`place`.`id`
GROUP BY `place`.`id`
ORDER BY viewCount DESC LIMIT 2,12현재 쿼리는 rating(별점) 과 cart(찜) 두 테이블을 조인해서
각각 평균값과 총 리뷰수, 총 찜수를 계산한다
이렇게 쿼리를 던졌을때 중복된 데이터가 생기므로
중복 제거를 위해 DISTINCT 를 사용했다
현재의 쿼리를 조금 더 효율적으로 개선하는 방법을 찾아보았다
서브 쿼리로 필요한 데이터만 추출하기
SELECT
`place`.`id`,
`place`.`address` AS address,
`place`.`image` AS image,
`place`.`title` AS title,
`place`.`mapx` AS mapx,
`place`.`mapy` AS mapy,
`place`.`view_count` AS viewCount,
`rating`.`averageRating`,
`rating`.`reviewCount`,
`cart`.`saveCount`
FROM
`place` `place`
LEFT JOIN
(SELECT
`placeId`,
AVG(`ratingValue`) AS `averageRating`,
COUNT(`placeId`) AS `reviewCount`
FROM
`place_rating`
GROUP BY
`placeId`
) AS `rating` ON `rating`.`placeId` = `place`.`id`
LEFT JOIN
(SELECT
`placeId`,
COUNT(`placeId`) AS `saveCount`
FROM
`cart`
GROUP BY
`placeId`
) AS `cart` ON `cart`.`placeId` = `place`.`id`
GROUP BY
`place`.`id`
ORDER BY
`viewCount` DESC
LIMIT 7, 12;이렇게 서브쿼리를 활용해서 필요한 데이터(평균 별점, 총 리뷰수, 총 찜 수)만 추출했다
결과

그런데 해당 소요시간은 매번 쿼리를 던질때마다 다르게 나온다
아마 네트워크 환경, 시스템 지연 시간을 포함한 전체 시간인거 같다
해당 소요시간 데이터로 쿼리의 성능을 측정하기엔 변수가 너무 많다
그래서 정확하게 쿼리만의 성능을 확인하기 위해
SET profiling = 1;profiling 을 설정해줬다
그리고 각각 기존 쿼리와 서브쿼리를 10번씩 실행해서 평균값을 확인해보자
기존 쿼리
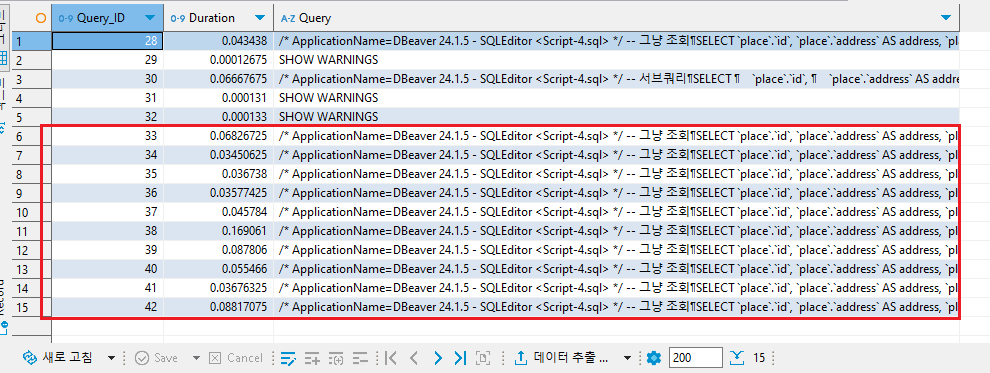
평균 Duration 값 = 0.065833675
약 65ms
서브 쿼리

평균 Duration 값 = 0.02303235
약 23ms
기존 쿼리와 서브쿼리 비교 결과
쿼리만의 성능은 65ms => 23ms로 약 3배 정도 증가한걸 볼 수 있다
불필요한 GROUP BY 제거
SELECT
`place`.`id`,
`place`.`address` AS address,
`place`.`image` AS image,
`place`.`title` AS title,
`place`.`mapx` AS mapx,
`place`.`mapy` AS mapy,
`place`.`view_count` AS viewCount,
`rating`.`averageRating`,
`rating`.`reviewCount`,
`cart`.`saveCount`
FROM
`place` `place`
LEFT JOIN
(
SELECT
`placeId`,
AVG(`ratingValue`) AS `averageRating`,
COUNT(`placeId`) AS `reviewCount`
FROM
`place_rating`
GROUP BY
`placeId`
) AS `rating` ON `rating`.`placeId` = `place`.`id`
LEFT JOIN
(
SELECT
`placeId`,
COUNT(`placeId`) AS `saveCount`
FROM
`cart`
GROUP BY
`placeId`
) AS `cart` ON `cart`.`placeId` = `place`.`id`
ORDER BY
`viewCount` DESC
LIMIT 1, 12;서브쿼리에서 집계 함수로 인해
각각의 placeId 에 대한 데이터를 계산해 주므로
place 테이블의 그룹화는 불필요하다
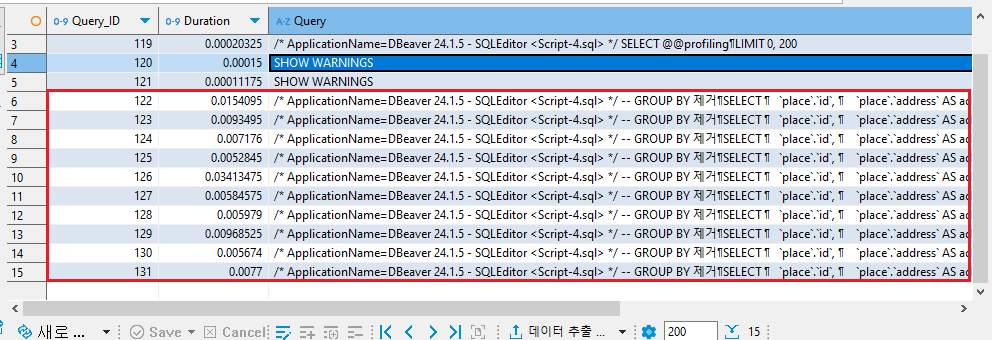
평균 Duration 값 = 0.010623825
약 10ms
서브 쿼리와 불필요한 GROUP BY 제거 결과 23ms => 10ms 로
성능 약 2배 증가
COUNT(*)로 변경
SELECT
`place`.`id`,
`place`.`address` AS address,
`place`.`image` AS image,
`place`.`title` AS title,
`place`.`mapx` AS mapx,
`place`.`mapy` AS mapy,
`place`.`view_count` AS viewCount,
`rating`.`averageRating`,
`rating`.`reviewCount`,
`cart`.`saveCount`
FROM
`place` `place`
LEFT JOIN
(
SELECT
`placeId`,
AVG(`ratingValue`) AS `averageRating`,
COUNT(*) AS `reviewCount`
FROM
`place_rating`
GROUP BY
`placeId`
) AS `rating` ON `rating`.`placeId` = `place`.`id`
LEFT JOIN
(
SELECT
`placeId`,
COUNT(*) AS `saveCount`
FROM
`cart`
GROUP BY
`placeId`
) AS `cart` ON `cart`.`placeId` = `place`.`id`
ORDER BY
`viewCount` DESC
LIMIT 1, 12;COUNT 값 계산시 placeId를 기준으로 삼기 보다
반환된 행(raw)으로 계산을 하는게 조금 더 빠를거 같았다
몇명이 리뷰와 찜을 한지만 알면 되기 때문이다

평균 Duration 값 = 0.00761315
약 7ms
총 성능 개선 결과
기존 쿼리 65ms => 7ms 성능 약 830% 개선
ORM 수정
//리뷰 서브 쿼리
const rating = this.ratingRepository
.createQueryBuilder()
.subQuery()
.select([
'rating.placeId AS placeId',
'AVG(rating.ratingValue) AS averageRating',
'COUNT(*) AS reviewCount',
])
.from(PlaceRating, 'rating')
.groupBy('rating.placeId')
.getQuery();
//찜 서브 쿼리
const cartSave = this.cartRepository
.createQueryBuilder()
.subQuery()
.select(['cart.placeId AS placeId', 'COUNT(*) AS saveCount'])
.from(Cart, 'cart')
.groupBy('cart.placeId')
.getQuery();
//메인 쿼리
const query = this.placeRepository
.createQueryBuilder('place')
.leftJoin(rating, 'rating', 'rating.placeId = place.id')
.leftJoin(cartSave, 'cart', 'cart.placeId = place.id')
.select([
'place.id',
'place.address AS address',
'place.image AS image',
'place.title AS title',
'place.mapx AS mapx',
'place.mapy AS mapy',
'place.viewCount AS viewCount',
'rating.averageRating AS averageRating',
'rating.reviewCount AS reviewCount',
'cart.saveCount AS saveCount',
])
.skip((searchOption.page - 1) * searchOption.limit)
.take(searchOption.limit);
참고한 글
'database' 카테고리의 다른 글
| 테이블 2개 JOIN시 COUNT값이 곱셈이 된다? (0) | 2024.08.17 |
|---|---|
| 시퀄라이즈 모델들 비동기적으로 연결하기 (0) | 2024.04.13 |
| ORM 사용 후기 (0) | 2024.04.11 |
| mariadb Node 환경에서 트랜젝션과 관리 (0) | 2024.04.02 |
| MySQL 자료형 (1) | 2024.03.14 |